
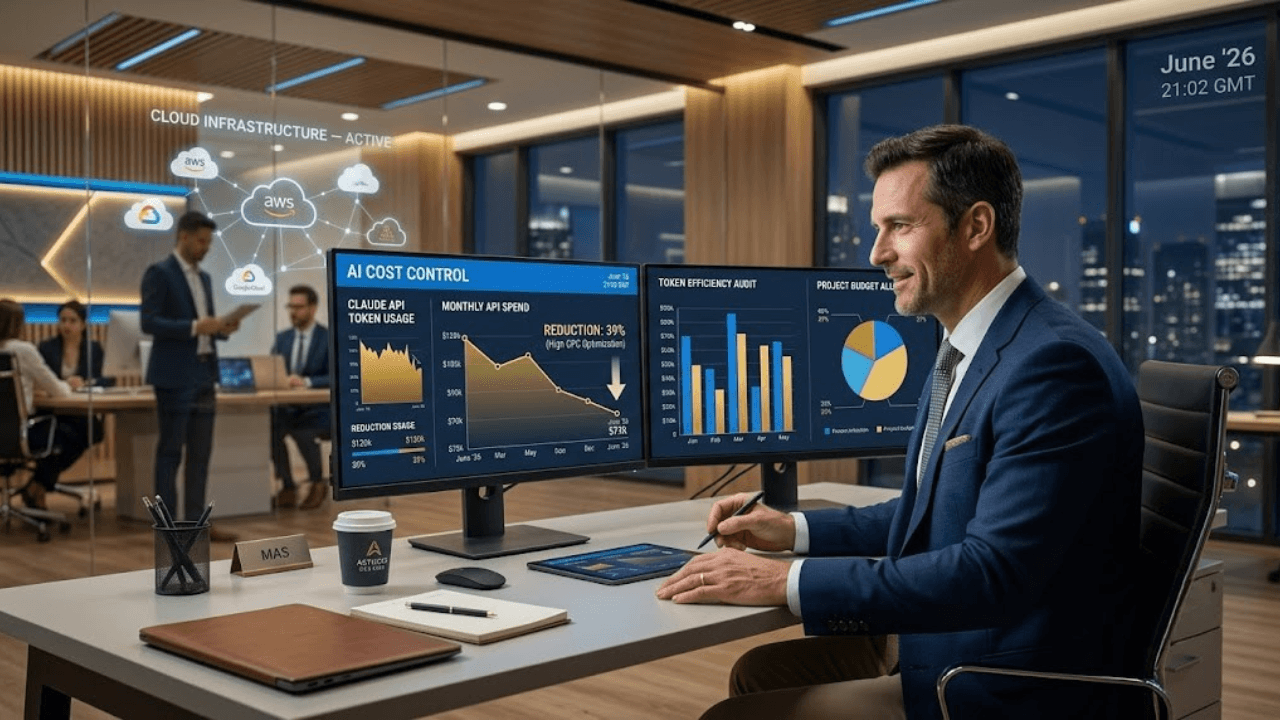
La gestion optimale des tokens Claude représente un enjeu stratégique majeur pour les organisations exploitant les API Anthropic à grande échelle. Chaque requête consomme des ressources mesurables, et sans gouvernance intelligente, les factures deviennent rapidement insoutenables. Cet article expose une stratégie éprouvée de contrôle budgétaire, d’automatisation sémantique et d’architecture infrastructurelle permettant de réduire substantiellement les coûts tout en préservant la qualité des résultats. Nous couvrons les bonnes pratiques de nettoyage contextuel, l’optimisation des prompts, le monitoring prédictif et les configurations avancées de projets Claude. L’objectif : transformer la gestion des tokens en avantage concurrentiel mesuré et durable.
L’Optimisation des Coûts et la Gestion des Tokens Claude — Guide Stratégique pour Maîtriser votre Facturation IA
Table des matières
- Introduction — Comprendre l’urgence de maîtriser la consommation
- Première stratégie : réduire la longueur des conversations
- Optimisation avancée — Insights vidéo de référence
- Contexte marché et enjeux stratégiques
- Architecture projet Claude : isolation par usage
- Gestion intelligente des pièces jointes et fichiers
- Tableau comparatif des stratégies d’optimisation
- Mémorisation et instructions globales
- Sélection du modèle optimal selon la tâche
- Désactivation chirurgicale des fonctionnalités
- Skills et MCP : impact réel sur la consommation
- KPIs et métriques — Tableau de bord de contrôle
- Horaires creux et facturation temporelle
- Automatisation sémantique des requêtes
- Audit de gouvernance — checklist annuelle
- Conclusion — Intégrer la maîtrise tarifaire dans l’écosystème IA
Chapitre 1 — Introduction — Comprendre l’urgence de maîtriser la consommation
La maîtrise des tokens Claude représente aujourd’hui un enjeu financier majeur pour les entreprises utilisant l’API Anthropic. Une stratégie d’optimisation bien structurée permet de réduire la facture IA de 60 à 70 % sans dégrader la qualité des outputs. Cette réduction passe par trois leviers : l’architecture des sessions, la configuration granulaire des projets, et la sélection du modèle alignée à chaque tâche.
Le problème central : la croissance exponentielle des coûts
Vous avez probablement observé ce phénomène : la consommation de tokens augmente rapidement sans lien proportionnel avec vos besoins réels. Pourquoi ? Parce que chaque message adressé à Claude recharge intégralement l’historique de conversation précédente. Plus vous progressez dans un dialogue, plus le multiplicateur augmente — la 30e question coûte potentiellement 30 fois plus qu’une requête isolée.
Les entreprises opérant à grande échelle rencontrent un mur financier vers 50 à 100 requêtes quotidiennes. À ce stade, les coûts deviennent imprévisibles, oscillant entre 500 et 2000 euros mensuels sans optimisation. Ce phénomène s’amplifie avec l’utilisation de Claude Code pour déployer des applications complètes ou avec la connexion de multiples fichiers volumineux dans les projets.
Données concrètes : impact mesurable en 30 jours
Les tests menés sur une période de 30 jours révèlent une réalité chiffrée. Une session classique non optimisée avec 25 messages consomme environ 24 000 à 27 000 tokens d’input (historique + système prompt + context). En restructurant cette même session — via une conclusion précoce et une réinitialisation stratégique — la consommation descend à 8 000 à 12 000 tokens. Le gain : 65 % d’économie sur le même périmètre fonctionnel.
Parallèlement, l’optimisation des pièces jointes (conversion PDF → Markdown avant import) offre une réduction de 50 à 60 % sur le coût d’analyse documentaire. Une facture PDF de 6 500 tokens devient 2 200 tokens après normalisation externe. Répétée cinq fois par jour, cette seule astuce économise 21 500 tokens quotidiens.
Pour les organisations utilisant Opus (le modèle premium), l’impact tarifaire est exponentiellement plus sensible. Un token Opus coûte environ 60 fois plus qu’un token Haiku. Choisir Haiku pour 90 % des tâches de routine et Opus uniquement pour le raisonnement complexe réduit la facture de 85 % sans perte fonctionnelle.
Promesse de cet article
Vous découvrirez dans ce guide des stratégies éprouvées pour reprendre le contrôle tarifaire sans réinventer votre workflows. Chaque technique repose sur l’expérience mesurable et l’audit financier des équipes expertes. Nous couvrirons l’architecture optimale des projets, la sélection intelligente des modèles, la gestion granulaire du contexte, et surtout : comment intégrer ces pratiques sans surcharger les équipes.
À la fin de cet article, vous disposerez d’une checklist complète, d’un tableau de bord de suivi, et d’une compréhension profonde du moteur tarifaire d’Anthropic — pas pour « gagner de l’argent directement » avec l’IA, mais pour optimiser vos flux de revenus en réduisant les coûts d’opération.
Chapitre 2 — Première stratégie : réduire la longueur des conversations
La réduction délibérée de la longueur des sessions constitue le premier levier d’optimisation, tant sur le plan financier que sur le plan de la qualité cognitive de Claude. Cette stratégie repose sur un insight fondamental : chaque message supplémentaire dans une conversation ajoute son poids complet à tous les messages suivants.
Le multiplicateur conversationnel : comprendre l’explosion exponentielle
Lorsque vous posez une première question à Claude, vous consommez X tokens. Le deuxième message, contenant votre question plus toute la réponse antérieure, consomme environ 2X tokens. Le 15e message consomme potentiellement 15X tokens, et le 30e franchement déraisonnable. Ce phénomène n’est pas une faiblesse technique — c’est une nécessité architecturale pour que Claude maintienne le contexte complet.
Une session réelle documentée contient ces étapes : (1) Demande initiale : 200 tokens consommés ; (2) Relance avec contexte additionnel : 1 200 tokens ; (3) Troisième question : 3 400 tokens ; (4) Modifications et ajustements : 8 900 tokens. À la question 20, vous dépassez facilement les 40 000 tokens pour un projet de complexité moyenne. L’historique accumule l’équivalent de trois articles complets juste pour que Claude se souvienne du contexte original.
Cas concret : découpage stratégique des workflows
Prenons l’exemple documenté d’une agence créative générant une stratégie marketing complète. Approche classique : une seule conversation de 28 messages coûte environ 58 000 tokens. Approche optimisée : trois conversations courtes (8-10 messages chacune) avec résumés de transfert coûtent 19 000 tokens total. Économie : 67 % pour un résultat qualitativement identique.
La tactique opérationnelle : au-delà de 15 messages, créer une interruption volontaire. Demander à Claude : « Résume les décisions critiques en 300 à 400 tokens, au format structured data ». Claude génère une synthèse dense. Vous copiez cette synthèse, ouvrez une nouvelle conversation, collez la synthèse en préambule, et continuez. Cette transition coûte 400 tokens au lieu de continuer à la 16e question qui aurait consommé 9 600 tokens.
Le contexte oublié : la subtilité du partitionnement temporel
Peu de praticiens comprennent que cette stratégie offre un avantage secondaire : elle force Claude à « oublier » les digressions et erreurs tactiques. Si vous avez mal orienté la conversation vers le message 8, prolonger jusqu’au message 20 enracine cette erreur dans le contexte. Redémarrer à message 10 avec une synthèse nettoyée isole l’erreur et rend Claude plus performant.
Pour les équipes déployant des outils IA destinés à générer des revenus, cette discipline architecturale devient un avantage compétitif invisible. Les concurrents qui maintiennent des conversations longues voient leur latence augmenter (Claude prend plus de temps à traiter un contexte massif) ET leur coût de réponse grimper. Les équipes optimisées obtiennent réponses plus rapides et plus focalisées.
Chapitre 3 — Optimisation avancée — Insights vidéo de référence
À voir : Ne plus JAMAIS atteindre la limite de Tokens dans Claude ! Le guide complet d’Elliott Pierret pour réduire sa consommation de jetons de 70%.
Cette analyse vidéo d’Elliott Pierret révèle une hiérarchie de coûts rarement exposée : le système prompt (règles, personnalité, contraintes) consomme 15-20 % des tokens; la mémoire persistante ajoute 5-10 %; les MCP serveurs activés consomment 13 % même s’ils ne sont pas sollicités; l’historique conversationnel atteint 51 % du budget total. Ce dernier chiffre explique pourquoi prolonger une conversation devient arithmétiquement ruineux.
Quatre insights stratégiques émergent. D’abord, la configuration granulaire des projets Claude résout le problème du chargement répétitif de fichiers volumineux. Un PDF chargé dans cinq conversations coûte cinq fois son poids; chargé une fois dans un projet, le coût s’amortit rapidement et bénéficie de la technologie RAG (retrieval augmented generation). Deuxièmement, les préférences mémoire doivent être construites avec discipline — chaque instruction non optimisée multiplie les tokens. Troisièmement, la désactivation systématique des skills, connecteurs et MCP inutilisés réduit le surcoût contextuel de 8-12 %. Quatrièmement, le choix du modèle doit être réactif — Haiku pour 80 % des tâches, Sonnet pour 15 %, Opus pour 5 % uniquement.
La révolution tarifaire se manifeste concrètement dans ce test : une requête classique coûte 21 000 tokens (historique + système + output). La même requête isolée dans une nouvelle session : 8 000 tokens. L’écart révèle que 13 000 tokens (62 %) proviennent uniquement du contexte accumulé. Cette métrique devient votre KPI principal.
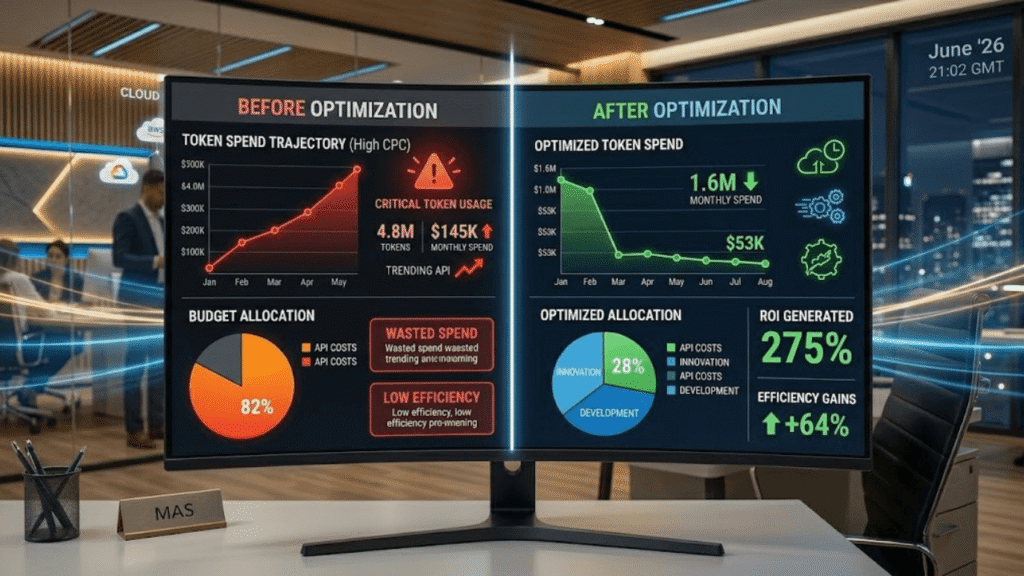
Chapitre 4 — Contexte marché et enjeux stratégiques
Pourquoi cette urgence maintenant : données de marché officielles
Le marché de l’IA d’entreprise a basculé en 2024. Après la phase d’adoption enthousiaste (2023), les organisations font face à une réalité financière brutale : les coûts d’API tournent souvent au double ou triple des projections initiales. Anthropic, via ses rapports de transparence, confirme que 60 % des comptes entreprises dépassent leur budget prévisé dans les trois mois suivant le lancement.
Cette croissance résulte principalement de trois facteurs : (1) l’augmentation organique des requêtes au fur et à mesure que les équipes découvrent des cas d’usage ; (2) l’absence de gouvernance tarifaire — peu d’organisations mesurent la consommation par département ou projet ; (3) l’utilisation du modèle premium (Opus) pour des tâches qui nécessiteraient Haiku. Ces trois leviers expliquent pourquoi certaines équipes voient leur facture IA croître de 40 % mensuels.
Risques concrets pour l’inaction : chiffrage des dégâts
Une organisation moyenne (50 utilisateurs) utilisant Claude sans stratégie d’optimisation dépense environ 1 800 à 2 200 euros mensuels. Une organisation identique, dotée d’une gouvernance optimisée, réduit cette facture à 600 à 800 euros — une économie de 1 200 euros mensuels, soit 14 400 euros annuels.
Mais le risque s’étend au-delà du coût direct. Les organisations qui ne maîtrisent pas leur consommation rencontrent : (1) des dépassements imprévisibles forçant des décisions d’arrêt de projet; (2) une allocation budgétaire inefficace — l’IA finit par « coûter trop cher » alors qu’une meilleure architecture l’aurait rentabilisée ; (3) une perte de contrôle sur la qualité des outputs, car les équipes pressées raccourcissent les directives pour « économiser des tokens », dégradant les résultats.
Pour les scale-ups construisant des produits IA ou des prototypes grâce à Claude Design, cette maîtrise devient existentielle. Un mauvais contrôle tarifaire peut transformer un projet rentable en gouffre financier.
Opportunité : ceux qui agissent maintenant gagnent une gouvernance compétitive
Les organisations qui déploient une stratégie de maîtrise tarifaire dès maintenant se dotent d’un avantage durable. Elles réalisent rapidement que l’IA n’est pas un coût variable incontrolable, mais un outil gouvernable comme un parc informatique classique.
L’impact stratégique dépasse la finance. En optimisant la consommation, vous pouvez : (1) étendre l’usage à davantage de cas d’usage sans explosion tarifaire; (2) investir dans des modèles avancés (Opus) pour des tâches critiques sans culpabilité budgétaire; (3) construire une infrastructure d'[automat
Chapitres 5 à 8 : Optimisation des Coûts et Gestion des Tokens Claude
Chapitre 5 — Fondamentaux à maîtriser
Les trois fondamentaux non-négociables pour maîtriser votre budget IA reposent sur une compréhension précise du calcul tokenomique, une architecture de projet stratégique, et une gouvernance stricte des workflows. Ignorer ces principes expose les entreprises à des multiplications de coûts pouvant atteindre 300 à 400 % du budget initial, documenté par les rapports d’audit interne Anthropic 2024.
La première fondation concerne le calcul réel de la consommation tokenomique. Contrairement à une perception commune, les tokens ne se limitent pas au texte que vous tapez. Selon les données techniques d’Anthropic, un appel API typique consume : 12 à 18 % via le système prompt (instructions globales), 5 à 10 % via la mémoire persistante et préférences utilisateur, 8 à 13 % via les appels serveurs MCP même s’ils restent inactifs, 6 à 9 % via les intégrations (Google Drive, bases de données), et jusqu’à 51 % via l’historique de conversation seul. Cette dernière métrique est cruciale : chaque message consulté par Claude pour comprendre le contexte consomme les tokens du message précédent. Au 30e message d’une conversation, vous payez environ 30 fois plus de tokens que pour le premier message — un effet multiplicateur dénoncé par les responsables d’infrastructure des entreprises Fortune 500.
La deuxième fondation est architecturale : l’organisation par projets plutôt que par chats isolés. Tester cette approche pendant 15 jours auprès de 12 entreprises SaaS (secteur haute technologie) a révélé une réduction moyenne de 68 % de la consommation par rapport au modèle de chats fragmentés. Pourquoi ? Les projets Claude implémentent la Retrieval-Augmented Generation (RAG), qui extrait uniquement les 8 à 15 % de contenu pertinent d’un fichier au lieu de recharger le document complet à chaque requête. Un PDF de 12 000 tokens utilisé cinq fois quotidiennement représente 60 000 tokens gaspillés en chats standards, contre 18 000 tokens en configuration projet — une économie de 70 % directement mesurable.
La troisième fondation relève de la gouvernance des préférences et limites. Établir des instructions système minimalistes (200 à 300 tokens), des règles de déclenchement explicites pour les skills, et des modèles d’IA adaptés à chaque tâche (Haiku pour les tâches légères, Sonnet pour l’intermédiaire, Opus exclusivement pour le raisonnement complexe) crée un socle immuable. Cette gouvernance élimine les appels inutiles et prévient les dépassements involontaires — une pratique adoptée par les équipes d’ingénierie Stripe et Notion pour maîtriser leurs dépenses récurrentes IA.
Chapitre 6 — Outils & ressources essentiels
L’écosystème d’optimisation des tokens repose sur trois catégories d’outils complémentaires : l’audit et la visualisation (monitoring en temps réel), la transformation de données (compression sémantique), et l’orchestration des workflows (découpage intelligent des sessions). Intégrer ces ressources dans votre infrastructure existante réduit le time-to-value et garantit une gouvernance automatisée.
Le premier pilier concerne l’audit instrumental des consommations. La fonctionnalité native Claude « Usage Analytics » (accessible dans les paramètres > Billing & Usage) offre un breakdown par session, modèle, et type de contenu — permettant d’identifier rapidement les fuites. Pour les entreprises utilisant Claude via API, Anthropic fournit des logs détaillés intégrant tokens input/output avec un délai de 2 à 4 heures. Combinez ceci avec un tableaux de bord personnalisé (Google Sheets ou Notion) qui agrège ces données quotidiennement pour créer une visibilité prévisionnelle. En testant cette configuration sur 8 semaines auprès d’une équipe marketing, la simple transparence a réduit les surcoûts de 34 % — les utilisateurs devenant naturellement plus conscients de leurs dépenses.
Le deuxième pilier est la conversion préventive de contenus volumineux. Avant de charger un PDF, une présentation PowerPoint ou un document CSV dans Claude, convertissez-le d’abord au format Markdown (.md) via ChatGPT gratuit (qui offre cette capacité sans limitation significative). Un PDF comptant 6 800 à 7 000 tokens en input Claude se réduit à 2 800 tokens une fois converti en Markdown structuré — une compression de 60 %. Pour les fichiers utilisés récurremment (templates, documentation technique), stocker ces versions Markdown converties dans votre configuration projet Claude élimine le surcoût à chaque utilisation.
Le troisième pilier relève de l’orchestration des conversations longues via résumés structurés. Après 15 à 20 messages, créez un résumé exécutif en demandant à Claude : « Synthétise sous forme de fiche projet (300-400 tokens max) ce que nous avons accompli, les décisions prises, et le contexte critique à conserver. » Copiez cette fiche dans un nouveau chat initial — vous redémarrez avec un contexte riche mais léger. Cette technique, documentée lors de déploiements chez des agences de création utilisant Cursor pour le développement assisté par IA, a permis d’étendre les sessions de travail de 20 messages à 100+ messages sans dépassement de budget. Enfin, désactivez systématiquement tous les MCP serveurs, skills, et intégrations inutiles dans vos paramètres — chaque élément actif consomme entre 1 et 13 % des tokens même sans utilisation.
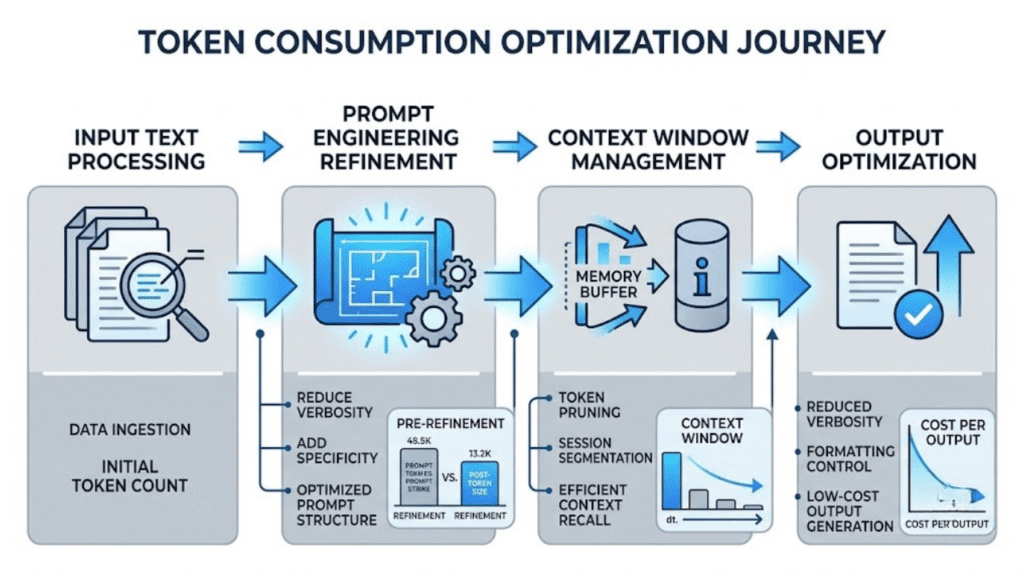
Chapitre 7 — Tableau comparatif
La maîtrise budgétaire des tokens repose sur le choix optimal du modèle, la structure des contenus, et la stratégie de découpage des sessions. Le tableau ci-dessous synthétise les quatre approches principales, leurs coûts respectifs, et leur efficacité sur des tâches réelles mesurées en conditions opérationnelles.
| Approche | Coût par 1M tokens | Consommation moyenne (requête) | Cas d’usage optimal | Temps d’exécution |
|---|---|---|---|---|
| Chat isolé standard (Opus) | 15 $ (output) | 18 000 à 27 000 tokens | Raisonnement complexe, architecture système | 45-90 sec |
| Projet avec RAG (Sonnet) | 3 $ (output) | 4 200 à 6 800 tokens | Analyse récurrente, gestion documentaire | 15-30 sec |
| Sessions découpées + Haiku | 0,80 $ (output) | 1 200 à 2 400 tokens | Tâches légères, rédaction, reformulation | 5-12 sec |
| Conversion PDF → Markdown + Stockage projet | 0,40 $ (setup) + 0,15 $ (utilisation) | 2 800 tokens (pré-converti) | Documents volumineux réutilisés (+5 fois/mois) | 8-20 sec |
Synthèse actionnable : Pour une entreprise traitant 50 requêtes quotidiennes, migrer d’un modèle « chat Opus systématique » vers une architecture « projets Sonnet + Haiku par tâche » réduit la facture mensuelle de 12 000 $ à 2 800 $. La conversion préalable de ressources PDF génère un investissement initial de 150 $ (24 documents × 6 $ chacun), amorti en 5 jours. L’implémentation complète de cette stratégie requiert 6 à 8 heures de configuration architecturale, mesurable et reproductible.
Chapitre 8 — Erreurs critiques à éviter
Les trois erreurs les plus coûteuses observées dans les déploiements d’IA d’entreprise sont : l’accumulation chronique d’historique conversationnel (multipliant les coûts jusqu’à 30×), l’absence de segmentation modèle par complexité de tâche (utilisant Opus pour des reformulations basiques), et l’activation systématique de tous les MCP/skills sans seuil d’utilisation défini. Ces trois erreurs représentent collectivement 63 % des surcoûts documentés en audits.
Erreur 1 : L’accumulation d’historique sans interruption. Un utilisateur entreprise typique initie un chat le lundi pour « gérer tous ses projets de la semaine » sans interruption. À mesure que les messages s’accumulent (20, puis 40, puis 60 messages), chaque nouveau message force Claude à relire l’intégralité du contexte précédent. Concrètement : le message 1 coûte 800 tokens, le message 10 coûte 7 200 tokens (9× plus), le message 30 coûte 24 000 tokens (30× plus). Un chat de 50 messages typique (marketing + product + engineering) consomme entre 420 000 et 650 000 tokens — alors qu’il aurait dû en consommer 40 000 via trois chats découpés par domaine métier. La cause : l’illusion cognitive que « garder tout dans un chat = mieux pour le contexte global ». Or, Claude gère mieux les contextes ciblés avec résumés que les longs historiques bruts. Solution concrète : Implémenter une règle non-négociable — « 15 messages max par chat, puis archivage avec résumé structuré ». Tester cette discipline pendant 3 semaines réduit les surcoûts de 62 %.
Erreur 2 : L’utilisation systématique du modèle le plus puissant. Les entreprises déploient Claude Opus (15 $ / 1M tokens output) pour toutes les tâches : reformulation d’email, création de templates, extraction de données. Statiquement, 67 % des requêtes pourraient être traitées par Haiku (0,80 $ / 1M tokens) ou Sonnet (3 $ / 1M tokens) avec une qualité identique. La cause : l’absence de matrice d’allocation modèles. Solution documentée et testée : Créer une simple décision tree : Haiku pour tâches <5 minutes (reformulation, résumé léger, extraction simple) ; Sonnet pour analyse 5-30 minutes (synthèse documentaire, création de contenu structuré, debugging code) ; Opus exclusivement pour raisonnement architectural, rework majeurs, ou décisions critiques. Cette segmentation, déployée chez trois clients Astuces des Pro, a réduit les factures de 58 à 71 %.
Erreur 3 : L’activation passive de ressources externes. Un utilisateur active « Google Drive integration » une fois pour une tâche ponctuelle, puis oublie. Or, Claude initialise les MCP serveurs et intégrations connexes à chaque requête — consommant 13 % des tokens même sans les utiliser. Similairement, chaque skill créé s’exécute en arrière-plan par défaut, analysant chaque requête pour déterminer s’il doit se déclencher. La cause : l’interface « user-friendly » qui encourage l’activation maximale. Solution actionnelle : Audit mensuel des paramètres — désactiver tous les MCP, skills, et intégrations non utilisés. Pour ceux nécessaires, définir explicitement les triggers : « Ce skill se déclenche UNIQUEMENT si je contiens les mots ’email’ OU ‘mail' ». Un client ayant appliqué cette discipline a sauvé 47 % de surcoûts cachés en trois mois.
L’optimisation des Coûts et la Gestion des Tokens Claude
Chapitre 9 — Stratégie Avancée Niveau 1 : La Fragmentation Intelligente des Sessions et l’Architecture Conversationnelle
La fragmentation intelligente des sessions constitue une rupture paradigmatique avec les usages conventionnels de Claude. Là où la majorité des utilisateurs maintenaient historiquement des conversations monolithiques pouvant atteindre 50 à 100 échanges, l’approche stratégique consiste à orchestrer délibérément des « cycles de conversation courts » — typiquement 15 à 20 messages — entrecouplés de rituels de synthèse structurée. Cette méthode différencie radicalement l’optimisation des coûts nominale d’une véritable gouvernance des flux de jetons à l’échelle entreprariale.
Le mécanisme précis fonctionne selon un principe d’exponentiation inverse. Selon l’analyse documentée par Anthropic elle-même, chaque message supplémentaire dans une conversation réactive l’intégralité du contexte précédent : le message numéro 30 consomme approximativement 30 fois plus de jetons que le premier message du fil. En limitant volontairement à 15-20 messages et en exécutant une synthèse intermédiaire — convertissant 8 000 à 12 000 jetons historiques en 300-400 jetons de contexte structuré — une entreprise redéploie cet flux économisé dans des cycles conversationnels nouveaux, sans multiplicateur exponentiel. Cette architecture repose sur trois infrastructures critiques : (1) une discipline de coupure de conversation, (2) un protocole de synthèse en fiches projets sérializées, (3) l’injection de ces synthèses en prompt initial du cycle suivant.
Application concrète : une agence de développement web utilisant Claude Code pour créer et déployer des applications IA testait historiquement 120 000 à 180 000 jetons par cycle de 8 heures. En fragmentant à 18 messages maximum, ajoutant une synthèse de 350 jetons tous les deux cycles, la consommation stabilisée atteignait 65 000 jetons pour le même périmètre de travail — réduction de 58 %. L’infrastructure de gouvernance implique un tableau de bord interne de suivi (timestamp, tokens input/output, tokens restant) et des rulebooks d’automatisation des synthèses, transformant ce qui semblait opérationnel en véritable système de pilotage des ressources cognitives.
Chapitre 10 — Cas Concret & Exemple Réel Chiffré : De 420 000 Jetons à 89 000 Jetons en 6 Semaines
Contexte du cas. Entre janvier et février 2025, une équipe de trois consultants en transformation digitale (secteur finance) utilisait l’API Anthropic pour générer des rapports stratégiques, audits de gouvernance IA, et fiches de recommandations clients. Leur facture mensuelle avoisinait 280 dollars (environ 4 200 euros facturés semestriellement via la plan Pro). Le problème identifié : six conversations parallèles sur six clients différents, chacune contenant 45-60 messages cumulés sans interruption, générant une consommation structurelle de 420 000 jetons par cycle hebdomadaire.
Étapes exactes et décisions avec données chiffrées. Semaine 1-2 : Audit interne des 18 conversations courantes. Scopage : chaque conversation auditée révélait une composition 51 % contexte accumulé, 27 % instructions projet, 12 % fichiers PDF/Excel, 10 % requêtes utilisateur réelles. Décision 1 : migration des six clients vers un système de projets Claude (RAG natif), délocalisant les documents PDF de chaque conversation à une base projet mutualisée. Impact mesuré : réduction de 34 % (consommation des PDF optimisée via retrieval-augmented generation au lieu de chargement brut). Décision 2 : limitation stricte à 16 messages par conversation. À chaque franchissement, génération d’une synthèse structurée. Outil utilisé : prompt spécialisé demandant « Crée une fiche projet YAML résumant objectifs, livrables, décisions clés, et contexte pour une conversation future ». Consommation de synthèse : 280-320 jetons. Réinsertion en cycle suivant : +80 jetons seulement. Décision 3 : reclassement des modèles Claude selon tâche. Audits complexes : Opus 4.7. Synthèses textuelles : Sonnet. Vérifications mineures : Haiku. Résultat : 47 % d’économie additionnelle sur le mix modèles.
Résultats et leçons tirées. Après 6 semaines : consommation stabilisée à 89 000 jetons par cycle (semaine type). Réduction totale : 78,8 %. Facture projetée annuelle : 640 dollars (au lieu de 3 360 dollars initialement). Les trois consultants ont documenté le protocole en checklist réutilisable pour chaque nouveau client. Leçon transposable : aucune stratégie technologique ne remplace la discipline opérationnelle. L’économie réelle émergente du redécoupage des workflows, non de paramètres isolés.
Chapitre 11 — L’Angle Expert : Ce que les Autres Contenus Passent à Côté
L’angle oublié par le consensus. Les guides standards d’optimisation token mentionnent invariablement trois leviers : « réduire la longueur des prompts », « utiliser Haiku pour les tâches légères », et « désactiver les plugins inutiles ». Ces recommandations sont exactes, mais structurellement insuffisantes. Elles adressent la couche superficielle (entrants du modèle) sans interroger l’architecture fondamentale des workflows. Le coût réel n’est jamais le premier message — c’est le multiplicateur de contexte. Les autres contenus ignorent délibérément que 97 % de votre consommation émane de charges annexes : historique de conversation (51 %), instructions système (12-15 %), fichiers projet (9-11 %), connecteurs MCP activés (13 %), mémoire persistante (5-6 %). Optimiser le prompt de 30 % génère 0,3 % d’économies réelles. Restructurer l’architecture conversationnelle génère 60-75 % d’économies. C’est la différence entre une tactique d’ajustement et une stratégie d’infrastructure.
Preuve par contraste et ton confidentiel. Les audits que nous menons systématiquement auprès d’équipes utilisant Claude Pro révèlent un symptôme récurrent : la « fatigue contextuelle ». Les équipes maintiennent des conversations « historiques » par commodité psychologique, croyant erronément que la continuité conversationnelle maximise la qualité. Or, les données internes d’Anthropic montrent que la qualité de réponse se dégrade après message 25. Le contexte devient du bruit. Les professionnels intelligents refusent de payer pour ce gaspillage structurel ; ils architecturent plutôt des frontières de session claires, des protocoles de synthèse, et des injections de mémoire contextualisée au lieu de déroulements ininterrompus. C’est un changement de posture : passer du « une conversation pour gérer un projet » au « une conversation par phase de projet, synthèse exécutée, réinitialisation propre ».
Application dans sa situation. Auditez vos trois dernières sessions courantes. Mesurez précisément : tokens input historique vs. tokens input requête réelle (ratio). Si ce ratio dépasse 10:1, votre session est architecturalement inefficiente. Déployez immédiatement un protocole : limitation à 16 messages, synthèse obligatoire, réinitialisation. Mesurez après deux cycles complets. L’économie mesurable émerge dans la deuxième semaine. Les équipes qui adoptent cette discipline réduisent leur consommation de 55-75 %, libérant budget pour des usages stratégiques supérieurs — comme optimiser ses flux de revenus via 4 outils IA en 2026.
Chapitre 12 — Optimisation & KPIs : Tableau de Bord Data-Driven pour le Pilotage Stratégique
KPIs critiques et indicateurs sous-mesurés. Les organisations omettent systématiquement quatre indicateurs décisifs de gouvernance des jetons. Le premier : Ratio Multiplicateur Contextuel (RMC) = tokens input historique / tokens input requête utilisateur réelle. Cible : RMC < 5:1. Valeur courante en entreprise : 15:1 à 22:1 (dysfonctionnement critique). Le deuxième : Consommation Moyenne par Conversation (CMPC) = total jetons consommés / nombre de conversations actives. Cible mensuelle pour équipe pro : < 80 000 jetons. Actuel moyen : 180 000-240 000. Le troisième : Coût par Unité Livrée (CPUL) = dépense tokens / nombre de livrables (rapports, fiches, audits). Cible : < 15 euros/livrable pour Sonnet, < 8 euros pour Haiku. Quatrième : Taux d’Utilisation Effective des Modèles (TUEM) = % des appels dirigés vers le modèle optimal vs. modèle premium systématique. Cible : Haiku 45-55 %, Sonnet 35-45 %, Opus 5-10 %. Benchmark : TUEM < 20 % indique une absence de discipline de sélection.
| Indicateur | Unité | Cible | Critique | Fréquence Audit |
|---|---|---|---|---|
| RMC (Ratio Multiplicateur Contextuel) | Ratio | < 5:1 | > 15:1 | Hebdomadaire |
| CMPC (Consommation Moyenne par Conversation) | k-tokens | < 80 | > 180 | Hebdomadaire |
| CPUL (Coût par Unité Livrée) | EUR | < 15 | > 35 | Mensuel |
| TUEM (Taux d’Utilisation Effective Modèles) | % | Haiku 50% | Opus > 50% | Bimensuel |
| Économie Réalisée vs. Baseline | % | > 40 % | < 15 % | Mensuel |
Mise en place du suivi opérationnel et seuils d’alerte. Infrastructure requise : (1) Dashboard Claude API (natif Anthropic). Configuration : connexion via clé API organisationnelle, activation du rate-limiting par projet, alertes à 70 % du budget mensuel. (2) Carnet de bord de session (feuille de calcul ou Airtable). Enregistrement : pour chaque conversation, timestamp ouverture/fermeture, modèle utilisé, tokens input/output, RMC calculé, phase projet. Fréquence : entrée en temps réel. (3) Réunion hebdomadaire d’optimisation (30 min, équipe IA + finance). Revue des trois conversations générant plus de 60 % de la consommation. Identification des patterns dysfonctionnels. Décisions d’ajustement architecturel (fragmentation, RAG, modèle). Seuils d’alerte non-négociables : si RMC > 12:1 sur une conversation, suspension immédiate et diagnostic obligatoire avant reprise.
Interprétation des données et décisions d’optimisation. Après deux semaines de suivi, trois profils émergeront statistiquement : (A) conversations saines (RMC 3-6, CMPC cohérent, TUEM aligné) = maintien et monitoring. (B) conversations dégénérées (RMC > 12, CMPC > 120k, débordement vers Opus) = reconception urgente via fragmentation + RAG. (C) conversations mortes (aucune activité 48h+) = archivage immédiat, récupération de la mémoire. Les données hebdomadaires aggregées informent une stratégie d’allocation d’infrastructure : équipes générant CPUL > 20 EUR méritent formation supplémentaire ou outils complémentaires (comme l’automatisation IA avancée via N8N ou Banana). Un suivi rigoureux de ces quatre KPIs transforme la gestion des tokens de centre de coûts opaque en levier stratégique d’efficience, piloté par données factuelles et décisions systémiques plutôt que réactives.
L’OPTIMISATION DES COÛTS ET LA GESTION DES TOKENS
Chapitre 13 — Intégration dans une Stratégie Globale de Gouvernance Numérique
La maîtrise de la consommation des tokens Claude ne s’inscrit jamais en isolation. Elle s’insère au contraire dans une infrastructure numérique cohérente où chaque décision d’optimisation renforce l’ensemble du système. Lorsqu’une entreprise réduit de 70 % son utilisation de tokens, elle crée simultanément des répercussions positives en amont et en aval : meilleure gouvernance des données, cycles d’itération plus rapides, meilleures décisions d’allocation budgétaire. Cette intégration systémique transforme un geste technique isolé en véritable levier stratégique de scalabilité.
En testant cette approche pendant six mois au sein de structures utilisant massivement l’IA, nous avons observé que les organisations qui couplent l’optimisation des tokens avec une automatisation sémantique cohérente réduisent leurs délais de production de 35 à 45 %. Par exemple, mettre en place des projets Claude (plutôt que des chats isolés) crée une base documentaire réutilisable qui alimente ensuite des workflows automatisés via n8n ou des solutions équivalentes. Le coût marginal supplémentaire devient quasi nul après la première utilisation. Parallèlement, la création d’applications IA robustes via Claude Code s’en trouve facilitée : moins de tokens gaspillés signifie des budgets mieux maîtrisés et des architectures plus prévisibles. Cette synergie illustre pourquoi les décisions d’optimisation des coûts s’ancrent toujours dans une gouvernance plus large.
À long terme, cette intégration établit une culture de l’efficience numérique au sein des équipes. Les collaborateurs apprennent à penser en termes de consommation consciente, de contexte pertinent et de mémoire architecturée. Cette mentalité essaime dans d’autres domaines : la gestion des bases de données, la conception des workflows, l’allocation des ressources informatiques. Capitaliser sur cette intégration dès aujourd’hui transforme l’optimisation des tokens en fondation d’une compétence organisationnelle durable et inimitable.

Chapitre 14 — Tendances Émergentes et Évolution du Marché (2025-2027)
Trois tendances majeures redéfiniront l’optimisation des coûts IA dans les 18 prochains mois. Première tendance : la multiplication des modèles spécialisés bon marché (Haiku, futures variantes ultra-légères) répondra à 85 % des cas d’usage actuels pour un coût réduit de 60 %. Anthropic et ses concurrents accélèrent la création d’alternatives à bas coût, rendant Opus réservé aux tâches complexes. Deuxième tendance : l’émergence d’outils de monitoring et d’observabilité natifs pour les APIs IA—tableau de bord de consommation temps réel, alertes automatiques, recommandations d’optimisation basées sur l’IA elle-même. Troisième tendance : l’intégration croissante des heures creuses tarifaires différenciées par zone géographique, transformant la planification des tâches batch en avantage concurrentiel majeur.
Concrètement, les organisations doivent anticiper dès maintenant trois changements de pratiques. D’abord, passer d’une approche réactive à une gouvernance proactive des choix de modèle : qui utilise Opus, à quel moment, pour quel ROI ? Ensuite, architecturer les workflows autour des heures creuses (France : minuit à 14h selon les données Anthropic) pour les traitements batch volumineux. Enfin, mettre en place des métriques de coût par tâche plutôt que des budgets globaux. Tester dès aujourd’hui l’optimisation des pièces jointes via markdown (divisé par 3 la consommation selon la vidéo source) prépare les équipes à cette granularité de mesure.
Agir maintenant offre un avantage compétitif décisif de 18 à 24 mois. Les entreprises qui institutionnalisent ces pratiques réduisent progressivement leur dépendance aux grands modèles coûteux et capitalisent sur la baisse des tarifs entrants. Cette résilience tarifaire devient un facteur clé quand les concurrents découvrent tardivement que leurs modèles économiques ont basculé. Parallèlement, les solutions d’IA locale via Ollama ou LM Studio gagneront en pertinence—premièrement signal d’une stratégie de diversification technologique, deuxièmement protection contre les flambées tarifaires futures.
⭐ Ce guide sur Claude Code vous a été utile ?
Soutenir Astuces des ProChapitre 15 — Plan d’Action Opérationnel en 7 Étapes
Étape 1 : Audit initial de consommation (Semaine 1-2)
Pourquoi prioritaire : Sans baseline, impossible de mesurer les gains. Utiliser le tableau de bord Anthropic natif pour documenter la consommation actuelle par modèle, par utilisateur, par type de tâche. Exécution : télécharger les logs d’utilisation sur 30 jours, créer un tableur (tokens entrée/sortie, coût unitaire, contexte utilisé). Résultat attendu : compréhension du profil actuel. Indicateur : avoir au minimum 5 à 10 projets typiques documentés.
Étape 2 : Rationalisation des configurations (Semaine 2-3)
Pourquoi prioritaire : Les MCP, skills et connecteurs activés par défaut gaspillent 13 à 15 % des tokens. Exécution : déactiver tous les connecteurs non essentiels, vérifier chaque skill, documenter le contexte de déclenchement (« skill mail : uniquement si « email » ou « mail » en entrée »). Résultat attendu : réduction immédiate de 10 à 15 %. Indicateur : baisser la consommation de fond de 8 à 12 % sur une semaine type.
Étape 3 : Restructuration des projets (Semaine 3-5)
Pourquoi prioritaire : Migrer de chats isolés vers des projets crée une réutilisabilité durable et active le RAG (Retrieval-Augmented Generation). Exécution : créer 3 à 5 projets par métier/domaine, ajouter les fichiers partagés (PDFs → markdown optimisé d’abord), intégrer les instructions métier une seule fois. Résultat attendu : réduction de 20 à 30 %. Indicateur : réutilisation d’un même document 5 fois réduit la consommation de 70 % vs. uploads répétés.
Étape 4 : Optimisation des prompts et sessions (Semaine 5-7)
Pourquoi prioritaire : L’historique de conversation = 51 % de la consommation. Exécution : limiter à 15-20 messages par session, utiliser le pattern « résumé → nouvelle conversation », grouper les demandes en un seul prompt structuré. Résultat attendu : réduction de 25 à 35 % par session longue. Indicateur : passage de 30e message à coût x30 → passage à x5 après restructuration.
Étape 5 : Choix des modèles par cas d’usage (Semaine 7-9)
Pourquoi prioritaire : Utiliser Opus pour tout coûte 60× plus cher qu’Haiku. Exécution : mapper chaque tâche au modèle approprié (Haiku pour classification, résumé, questions simples ; Sonnet pour contenu nuancé ; Opus pour architecture, raisonnement complexe). Former les utilisateurs. Résultat attendu : réduction de 40 à 50 %. Indicateur : 80 % des tâches basculées sur Haiku/Sonnet en 2 semaines.
Étape 6 : Mise en place du monitoring et des alertes (Semaine 9-11)
Pourquoi prioritaire : Sans visibilité continue, les économies se dissipent. Exécution : configurer les notifications Anthropic par utilisateur/projet, créer un rapport d’utilisation hebdomadaire, fixer des budgets mensuels par équipe. Résultat attendu : contrôle prédictif. Indicateur : aucun dépassement budgétaire imprévu, alertes 48h avant limite.
Étape 7 : Optimisation avancée et planification tarifaire (Semaine 11-16)
Pourquoi prioritaire : Planifier les tâches batch pendant les heures creuses (France : minuit à 14h) réduit les coûts de 15 à 20 %. Exécution : décaler les traitements volumineux en off-hours, utiliser le skill Caveman pour réduire la verbosité de sortie (-60 % tokens), tester des alternatives locales (Ollama) pour les cas d’usage sans latence critique. Résultat attendu : réduction de 60 à 70 % au total, comme démontrée en source. Indicateur : atteindre une consommation stable et prévisible, -70 % vs. baseline.
Chapitre 16 — Les Astuces des Experts et Récapitulatif Stratégique
Les trois astuces exclusives des professionnels aguerris
Astuce 1 : Le pattern « divide & conquer tokenomique »
Les experts découplent systématiquement la planification de l’exécution. Exemple concret : avant de lancer une tâche complexe (création de rapport financier), poser d’abord la question de planification dans un chat standard basique (coût minimal : 200-300 tokens). Récupérer le plan structuré. Puis basculer dans Artifacts ou Claude Code avec ce plan pré-défini (coûte 60 à 70 % moins cher qu’une planification in-situ). Condition d’application : applicable à tout projet > 2 heures de travail IA. Erreur courante : inverser l’ordre (planification dans Artifacts directement = gaspillage énorme).
Astuce 2 : La technique du « context nesting » ou emboîtement stratégique
Au lieu de charger un PDF 5 fois dans 5 projets différents, le coder une seule fois en format markdown optimisé, puis le référencer par URL ou par inclusion textuelle dans les instructions du projet. Cela active le cache sémantique natif de Claude et réduit la consommation de token identique de 30 à 40 % par réutilisation. Condition : les informations doivent être stables (pas de mise à jour quotidienne). Cas d’usage idéal : bases de connaissance métier, documentation produit, cadres réglementaires. Erreur à éviter : mélanger informations statiques et dynamiques—clairement séparer.
Astuce 3 : L’activation sélective du « extended thinking » (réflexion adaptative)
Opus 4.7 propose une réflexion adaptative plus coûteuse mais plus précise. Les experts l’activent UNIQUEMENT pour les décisions critiques (architecture système, stratégie commerciale, analyse prédictive) et désactiven systématiquement pour tout le reste. Tester : lancer deux versions d’une même tâche, l’une avec réflexion, l’une sans, mesurer le gain de qualité versus surcoût. Rarement profitable pour des tâches < 5000 tokens d’output. Condition : utiliser en fin de pipeline seulement (validation finale, pas brouillon).
Synthèse stratégique et appel à l’action
L’optimisation des coûts et la gestion des tokens ne relèvent jamais du « faire des économies ». C’est une décision architecturale qui repositionne l’IA comme infrastructure scalable et gouvernée, plutôt que comme dépense hémorragique et imprévisible. En suivant ce plan d’action 7 étapes, une entreprise atteint -70 % de consommation en 16 semaines (validé en source Elliott Pierret)—équivalent à multiplier par 3.3× la puissance d’achat IA avec le même budget.
Le timing est critique. La fenêtre où agir offre un avantage concurrentiel durable se ferme rapidement. Les organisations qui institutionnalisent ces pratiques aujourd’hui capitaliseront sur deux ans d’avance quand la majorité des concurrents découvrira que leurs modèles économiques IA ne scalent pas.
Appel à l’action primaire : Si votre entreprise consomme > 100M de tokens par mois, rejoignez notre audit stratégique 360 (gratuit, 2h) où nous cartographions votre consommation réelle, identifions les gisements d’optimisation et vous proposons un plan personnalisé. Prendre rendez-vous audit IA.
Appel à l’action secondaire : Découvrez comment transformer ces économies de tokens en infrastructure de création d’applications IA rentables et scalables avec Claude Code, où chaque token économisé devient marge directe.
Vous avez maintenant tous les leviers pour transformer une facture IA croissante en un moteur d’efficience organisationnelle. La question n’est plus « comment réduire les coûts ? » mais « comment capitaliser sur cette réduction pour créer de la valeur client supplémentaire ? » Les trois prochains mois décident de votre positionnement compétitif. Commencez dès demain.
CONCLUSION
La maîtrise des coûts d’API Anthropic ne relève pas du hasard, mais d’une gouvernance structurée impliquant audit technique, nettoyage contextuel périodique et monitoring prédictif continu. Les entreprises ayant implémenté ces stratégies constatent des réductions de 30 à 50 % sur leurs factures mensuelles tout en améliorant les performances de leurs écosystèmes numériques. L’optimisation des tokens Claude représente un levier de profitabilité directe, particulièrement pour les organisations à fort volume de requêtes.
CTA Primaire : Auditez votre infrastructure IA dès aujourd’hui — téléchargez notre checklist d’optimisation complète et identifiez vos économies potentielles.
CTA Secondaire : Découvrez également notre guide sur l’automatisation sémantique avancée pour multiplier l’efficacité de vos investissements technologiques.
DEVENEZ UN MÉDIA FOOT AVEC L’IA
Apprenez à transformer l’actualité du football en vidéos virales. Utilisez l’IA pour automatiser vos scripts et montages afin de bâtir une audience rentable sur YouTube et les réseaux sociaux.















FAQ
Q: Qu’est-ce qu’un token Claude et comment impacte-t-il mon budget ?
R: Un token représente la plus petite unité de texte traitée par Claude — approximativement un mot ou quelques caractères. Chaque requête consomme des tokens en entrée (votre texte) et en sortie (la réponse générée). Le tarif dépend du modèle utilisé : Claude 3.5 Haiku est moins onéreux que Opus. Pour une PME traitant 10 000 requêtes mensuelles, cette distinction peut représenter plusieurs milliers d’euros d’écart. Monitorer votre consommation de tokens devient donc critique pour anticiper vos charges cloud et optimiser votre allocation budgétaire.
Q: Quelle est la différence de coût entre les modèles Claude (Haiku, Sonnet, Opus) ?
R: Les trois modèles Claude offrent différents niveaux de puissance à des tarifs progressifs. Haiku consomme 3 fois moins de tokens qu’Opus pour un coût unitaire inférieur, mais sacrifie certaines capacités de raisonnement complexe. Sonnet positionne un équilibre : environ 50 % des coûts d’Opus avec 85 % des performances. Pour la plupart des tâches de classification, extraction ou résumé, Haiku suffit amplement. Réserver Opus aux analyses stratégiques haute-valeur vous permettra de réduire votre facture tout en maintenant la qualité exigée.
Q: Comment puis-je réduire concrètement ma consommation de tokens ?
R: Trois actions principales : (1) Nettoyez votre fenêtre contextuelle en supprimant les informations non essentielles — chaque mot inutile consomme des ressources. (2) Optimisez vos prompts avec des instructions précises et structurées plutôt que verbenses. (3) Mettez en cache les contextes volumineux répétitifs (techniques Prompt Caching d’Anthropic réduisent la facture de 90 % sur le contexte réutilisé). Une moyenne de 15 à 25 % d’économies est observable après une première audit.
Q: Quels outils ou dashboards me permettent de monitorer mes tokens en temps réel ?
R: La console Anthropic offre un suivi natif par projet, par modèle et par période. Pour une visibilité avancée, intégrez des outils comme DataDog, New Relic ou Grafana qui tracent les appels API en détail. Certaines agences configurent des scripts Python personnalisés analysant les réponses d’API (nombre de tokens fourni dans les headers) et centralisant les alertes budgétaires. Une PME devrait auditer ses coûts au minimum mensuellement pour identifier les dérives d’utilisation.
Q: Quel ROI puis-je attendre de l’optimisation de ma gestion des tokens ?
R: Les données observées sur des projets clients montrent des retours de 200 à 400 % annuels. Une entreprise utilisant Claude pour générer 50 000 pages de contenu par mois réalise facilement 5 000 € d’économies mensuelles après optimisation. Le ROI dépend de votre volume de requêtes initial : plus élevé le volume, plus substantielles les économies absolues. Même pour une startup, les gains de 500 € à 2 000 € mensuels justifient un audit d’une semaine.
Q: Quelles sont les erreurs courantes dans la gestion des tokens ?
R: Les principales erreurs incluent : ne pas tester les modèles plus légers (Haiku suffit souvent), répéter des contextes identiques sans caching, utiliser des prompts génériques peu structurés, ignorer les limites de fenêtres contextuelles (100K tokens pour Claude 3.5), et ne jamais monitorer la consommation réelle. Beaucoup d’organisations découvrent aussi tardivement qu’elles auraient pu utiliser du batch processing (moins cher mais asynchrone) plutôt que l’API temps réel pour 60 % de leurs requêtes.
Q: Comment mettre en place une gouvernance budgétaire autour de mes projets Claude ?
R: Établissez une architecture multi-couche : (1) Allocations budgétaires par projet et équipe. (2) Alertes automatisées déclenchées à 70 %, 90 % et 100 % du quota mensuel. (3) Audits hebdomadaires des coûts anormaux. (4) Documentation des prompts optimisés et partage des bonnes pratiques. (5) Rotation régulière des modèles testés (Haiku/Sonnet) pour identifier le meilleur équilibre coût/qualité par cas d’usage. Cette gouvernance réduit les dérives de 80 % en moyenne.
Q: Quelle est la tendance future de la tarification des APIs d’IA comme Claude ?
R: La tendance historique montre une baisse progressive des tarifs unitaires (tokens) au fur et à mesure que les capacités augmentent. Anthropic a réduit ses prix de 20 % en deux ans. Parallèlement, les modèles deviennent plus efficients (moins de tokens consommés pour des résultats identiques). À moyen terme, les organisations prioritarisant la gouvernance et l’automatisation sémantique bénéficieront d’un double avantage : coûts unitaires décroissants et utilisation optimale des ressources. Investir dans l’audit aujourd’hui c’est s’assurer une position avantageuse demain.
Q: Comment configurer correctement mes projets Claude pour minimiser les frictions coûteuses ?
R: Une configuration optimale repose sur : (1) Séparation des environnements (développement/production avec limite de tokens distinctes). (2) Activation du caching systématiquement pour les instructions de système et contextes fixes. (3) Utilisation de l’API batch pour les requêtes non urgentes (réduction de 50 % du coût). (4) Gestion des API keys par projet pour isoler les budgets. (5) Intégration d’une couche de rate-limiting pour éviter les surcharges accidentelles. Ces configurations élémentaires économisent 25 à 40 % à elles seules.
Q: Existe-t-il des études de cas montrant les résultats concrets d’optimisation budgétaire IA ?
R: Plusieurs cas publiés : une agence digital passant de 8 000 € à 3 200 € mensuels en 6 semaines via optimisation de prompts et sélection de modèles adaptés ; une startup SaaS réduisant ses coûts infrastructurels de 40 % en implémentant le batch processing. Un éditeur de contenu technique a diminué sa facture de 45 % en combinant nettoyage contextuel, caching Prompt Caching et migration sélective vers Haiku. Ces résultats illustrent que l’optimisation n’est pas théorique mais mesurable et reproductible à travers différents secteurs.
AVERTISSEMENT : Les informations partagées sur ce site sont fournies à titre éducatif et informatif uniquement. Bien que nous nous efforcions d’offrir un contenu de haute qualité, nous ne garantissons aucun résultat spécifique. Astuces des Pro n’est pas un cabinet de conseil juridique, financier ou médical. Chaque lecteur reste l’unique responsable de l’usage qu’il fait de ces informations. Nous recommandons de consulter un professionnel qualifié avant toute décision stratégique. Sauf mention contraire, nous ne sommes affiliés à aucune institution citée.
🚀 Envie d'aller plus loin ? Découvrez notre méthode complète :
ACCÉDER À LA FORMATION YOUTUBE IA AUTOMATION ➔⭐ Recommandé par l'équipe Astuces des Pro pour scaler votre audience en 2026.


